Forensic DNA Profiles Crossing Borders in Europe (Implementation of the Treaty of Prüm)
Custodian Dutch DNA DatabaseNetherlands Forensic InstituteThe HagueThe Netherlands
Publication Date: 2011
Introduction
This article describes the implementation of the Treaty of Prüm, which enables European countries to search each other's DNA databases in an automated way. Different aspects will be illustrated in this article: the scope of the Treaty of Prüm, its implementation status, the software used for the exchange of DNA profiles, the Prüm inclusion and matching rules, the different types of matches that are produced, the results obtained, the prevention of false-positive matches and the detection of false-negative matches. The article will end with some conclusions.
Scope of the Treaty of Prüm
The treaty includes cross-border cooperation by means of exchanging judicial and police information and by providing mutual assistance. With regards to the exchange of information, each member state has to make its fingerprint, DNA and vehicle registration databases available to other member states for automated searches on a hit/no hit basis. After a match personal data and case information are exchanged between countries by existing mutual legal assistance procedures (police or judicial).
Prüm Implementation Status
The treaty was signed in 2005 by Austria, Germany, France, Spain, Belgium, Luxembourg and the Netherlands. These countries were later joined by Finland, Portugal, Slovenia, Sweden, Bulgaria, Greece, Italy, Slovakia, Romania and Hungary. On 23 June 2008, the Treaty of Prüm was converted into European Union (EU) legislation by two Council Decisions (2008/615/JHA and 2008/616/JHA). By 26 August 2011, all 27 EU countries should have implemented the council decisions, but many countries are not ready yet. The non-EU countries of Switzerland, Norway, Liechtenstein and Iceland are allowed to join the Prüm operation. Norway and Iceland have already requested this, and the EU has agreed. At the moment of submission of this article, 11 countries were operational for DNA analysis (Austria, Germany, Slovenia, Spain, Luxembourg, Finland, France, Bulgaria, Slovakia, the Netherlands and Romania). However, not every country is operational with all other countries yet because some countries need more time to start the exchange of DNA profiles (testing the TESTA connection and the software, exchange of certificates, etc.).
Prüm Software
The Prüm software was developed jointly by DNA and IT experts from the Bundeskriminalamt (BKA) in Germany, the Ministry of the Interior of Austria and the Netherlands Forensic Institute in the Netherlands. From the Prüm database of a country, DNA profiles can be sent to other countries for comparison to their Prüm databases. A country can decide to send a DNA profile to one or more selected countries or to all operational countries to which it is connected. Figure 1 shows the automated flow of information.
1. DNA profiles that meet the Prüm inclusion rules (see below) are copied from the National DNA database (N-DNA-DB) to the Prüm database of a country at a predetermined frequency. The Prüm database of a country can either be a physical copy or a view of the National DNA database.
2. From the Prüm database, DNA profiles can be sent to other countries.
3. This is done using the Communication Tool, which converts the DNA profile into an encrypted e-mail attachment.
4. The e-mail is sent to one or more other countries via the secure European TESTA network.
5. The e-mail arrives at the e-mail server of the requested country.
6. The Communication Tool of the requested country picks up the e-mail attachment and decrypts it.
7. The Communication Tool of the requested country puts the DNA profile in the Request and Response Database of that country.
8. The Matching Tool of the requested country picks up the DNA profile from the Request and Response Database.
9/10. The Matching Tool of the requested country compares the DNA profile with the Prüm database of that country.
11. The Matching Tool puts the result of the comparison back in the Request and Response Database of the requested country, where it can be viewed via the Graphical Use Interface.
12. The Communication Tool of the requested country picks up the result of the comparison.
13. The Communication Tool of the requested country converts the result of the comparison into an encrypted e-mail attachment.
14. The e-mail is sent to the requesting country via the secure European TESTA network.
15. The e-mail arrives at the e-mail server of the requesting country.
16. The Communication Tool of the requesting country picks up the e-mail attachment and decrypts it.
17. The Communication Tool of the requesting country puts the result of the comparison in the Request and Response Database of that country, where the results can be viewed via the Graphical User Interface.
Note that the results of a comparison can be viewed by both the requesting and requested country.
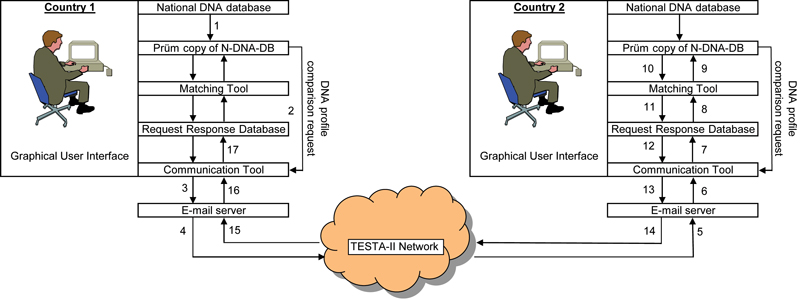 Figure 1. The automated flow of information.
Figure 1. The automated flow of information. In 2009 the FBI decided to build all functions necessary to join the Prüm operation in CODIS. Figure 2 shows the flow of information when this version of CODIS is used. In the second half of 2011 all CODIS-using European countries will get the new version of CODIS to enable them to join the Prüm operation. At the time of writing this article the Netherlands was already using this new version of CODIS for the international exchange of DNA profiles and at the time of publication probably many more countries will be using it.
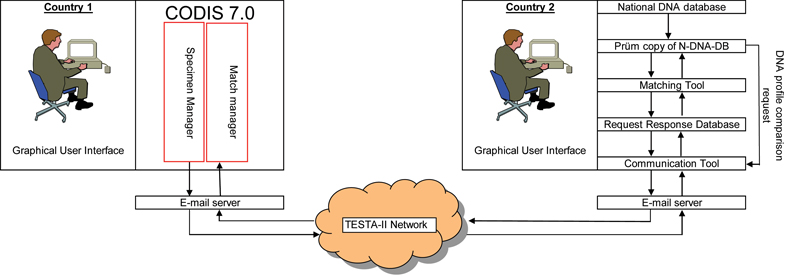 Figure 2. International exchange of DNA profiles with CODIS.
Figure 2. International exchange of DNA profiles with CODIS. Prüm Inclusion Rules
DNA profiles have to meet certain criteria to be included in international comparisons:
- Must include at least 6 of the 7 old ESS1 loci for known persons
- Must include at least 6 ESS loci for crime scene stains
- Must include any other of the 24 old1 Interpol loci
- One allele of a locus can be a wildcard
- No mixed profiles (a maximum of two values per locus) are allowed
- No profiles that have already matched a person are allowed
- No profiles that a country does not want to make available (e.g., DNA profiles of laboratory personnel kept for contamination detection purpose)
1The European Standard Set (ESS) has recently been extended by five additional loci.
Prüm Matching Rules
The software produces a match when there are at least six fully matching loci between two DNA profiles. In addition, one deviation (wildcard or mismatch) is allowed, and this is called a near match. Any type of profile sent for a comparison will be compared to any type of DNA profile available for comparison, so the following types of matches can occur: stain-stain, stain-person or person-person. Matches can be of different qualities:
- Quality 1: All alleles of all loci that can match are identical (see Figure 3, Panels A and B, for examples)
- Quality 2: One of the two matching profiles contains a wildcard
- Quality 3: One of the alleles of one locus contains a mismatch of one base pair (e.g., 9.2 ↔ 9.3)
- Quality 4: One of the alleles of one locus contains a mismatch of more than one base pair (e.g., 22 ↔ 26)
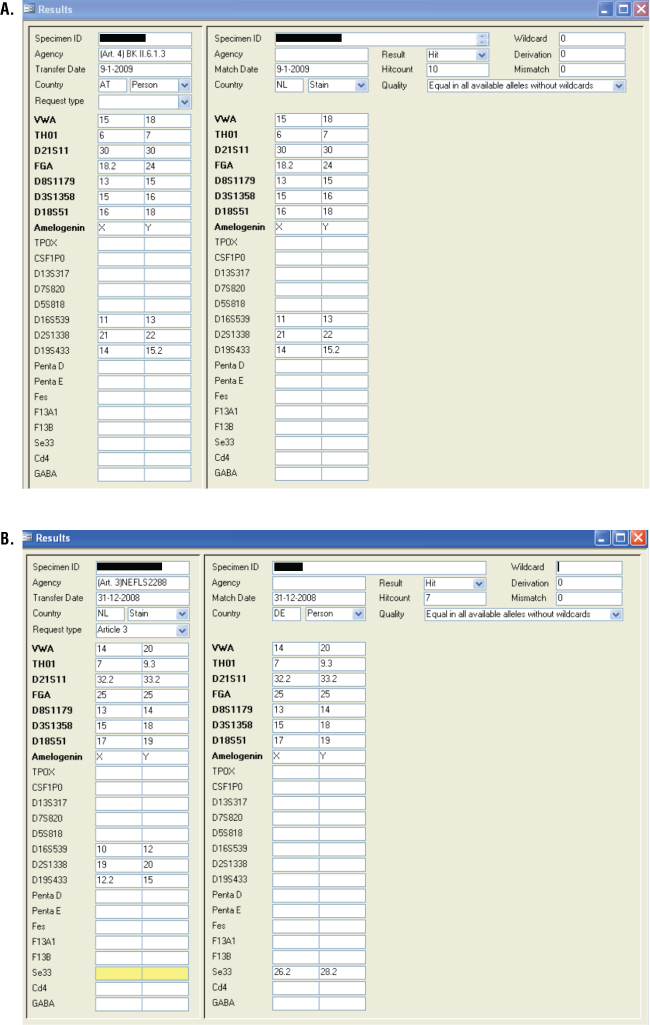 Figure 3. Matching DNA profiles.
Figure 3. Matching DNA profiles.
Panel A. Full match between a Dutch and an Austrian DNA profile (Q1). Panel B. Full match between a Dutch and a German DNA profile (Q1).
Number of Profiles Exchanged
Table 1 shows how many DNA profiles were sent and received by the Netherlands during the first three years of operation.
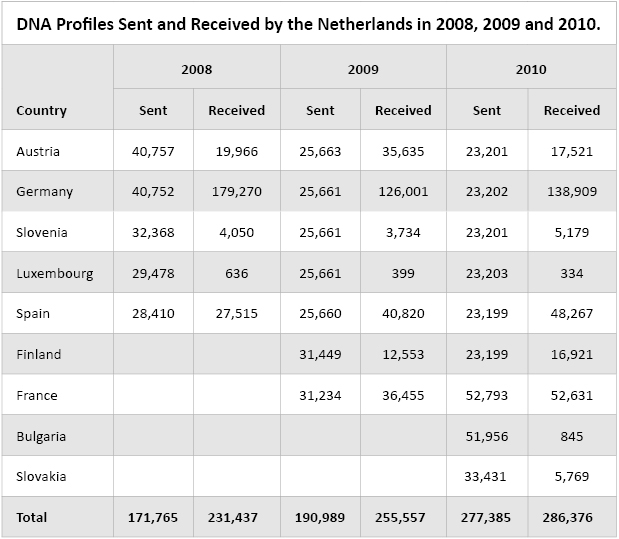 Table 1. DNA Profiles Sent and Received by the Netherlands in 2008, 2009 and 2010.
Table 1. DNA Profiles Sent and Received by the Netherlands in 2008, 2009 and 2010. When two countries start to exchange DNA profiles with another country, both countries first send all their unidentified stain profiles to each other. As of that moment the preferred way of working, which is also used by the Netherlands, is to send each other all new (and modified) profiles of both stains and persons. By sending each other all new profiles of persons, there is no need for repeatedly sending each other DNA profiles of stains that have not yet matched a person to see if they match with the newly added person profiles in the DNA database of the other country. You only have to wait for matches with old unidentified stains. If a person who matches your old unidentified stain is included in a foreign DNA database, you will get the match in your own DNA database when the DNA profile of the person is sent to you. By this way of working, there is a minimum of data exchange to get a maximum result: a complete comparison of all stain profiles of one country with all person profiles of the other country and vice versa.
Results
Table 2 shows the cumulative international match results obtained in the Netherlands as of 1 July 2011.
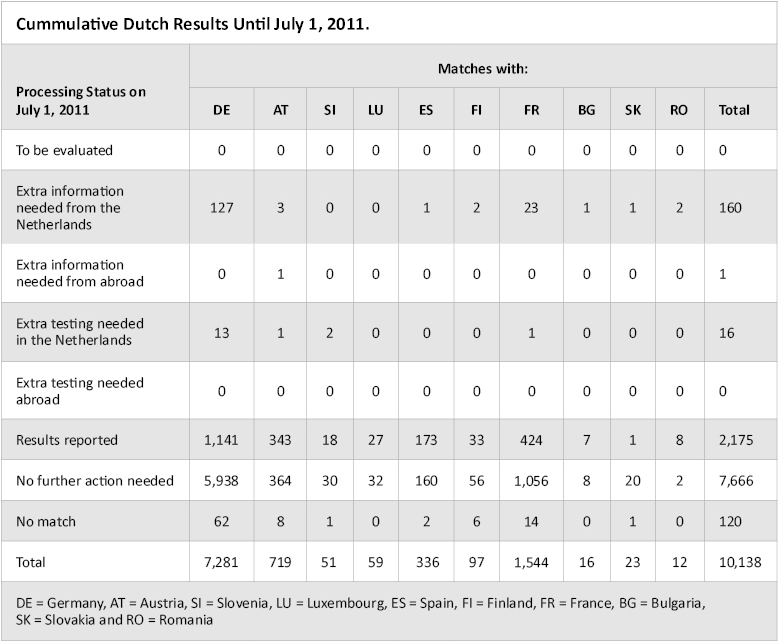 Table 2. Cumulative Dutch Results with Germany (DE), Austria (AT) Slovenia (SI), Luxembourg (LU), Spain (ES), Finland (FI), France (FR), Bulgaria (BG), Slovakia (SK) and Romania (RO) until July 1, 2011.
Table 2. Cumulative Dutch Results with Germany (DE), Austria (AT) Slovenia (SI), Luxembourg (LU), Spain (ES), Finland (FI), France (FR), Bulgaria (BG), Slovakia (SK) and Romania (RO) until July 1, 2011. Some results don’t require further action. Some reasons for this are:
- Duplicate matches
- Predecessors of improved matches
- Matches with Dutch convicted persons (unless they are wanted)
- Low-priority matches (for the Netherlands)
- False-positive matches
False-Positive Matches
According to the Prüm matching rules, the minimum number of matching loci is 6. However, it can simply be calculated that 6- and 7-locus matches have a non-negligible chance of being false-positive. Sometimes a false-positive match can be recognized immediately, but most of the time additional DNA testing is necessary to verify or disprove a false-positive match. Figure 4 shows a 6-locus match of a Dutch stain with two different German persons. Additional DNA testing showed that neither of these two persons was the donor of the stain.
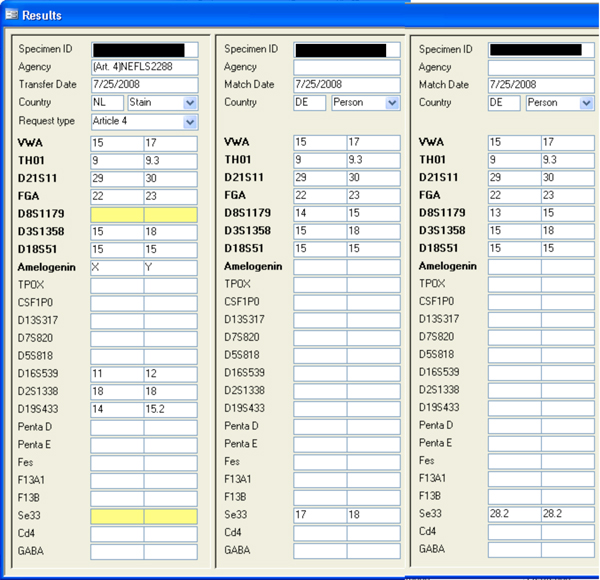 Figure 4. Example of what later proved to be false-positive 6-locus matches between a Dutch stain and two German persons.
Figure 4. Example of what later proved to be false-positive 6-locus matches between a Dutch stain and two German persons. Since the start of the Prüm operation in the Netherlands in 2008, many 6- and 7-locus matches have undergone additional DNA testing. Table 3 shows how many 6- and 7-locus matches proved to be false-positive after additional DNA testing.
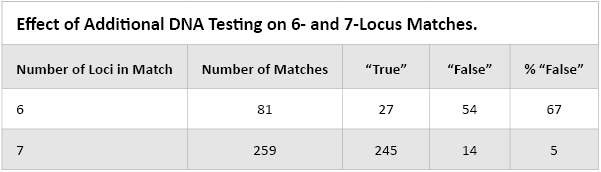 Table 3. Effect of Additional DNA Testing on 6- and 7-Locus Matches.
Table 3. Effect of Additional DNA Testing on 6- and 7-Locus Matches. False-Negative Matches
A false-negative match is a match that should be found but is not found because one of the DNA profiles contains a mistake. Mistakes may be caused by allele-calling errors, typing errors, allele dropouts due to low-level DNA testing or a primer binding-site mutation, etc. To detect false-negative matches one mismatch is allowed by the Prüm matching software. These are called near matches. After finding a near match, both countries check their original electropherograms to check for possible mistakes. If no mistake can be found the result is “no match”. Figure 5, Panels A and B, shows examples of false-negative matches that were detected by this search configuration.
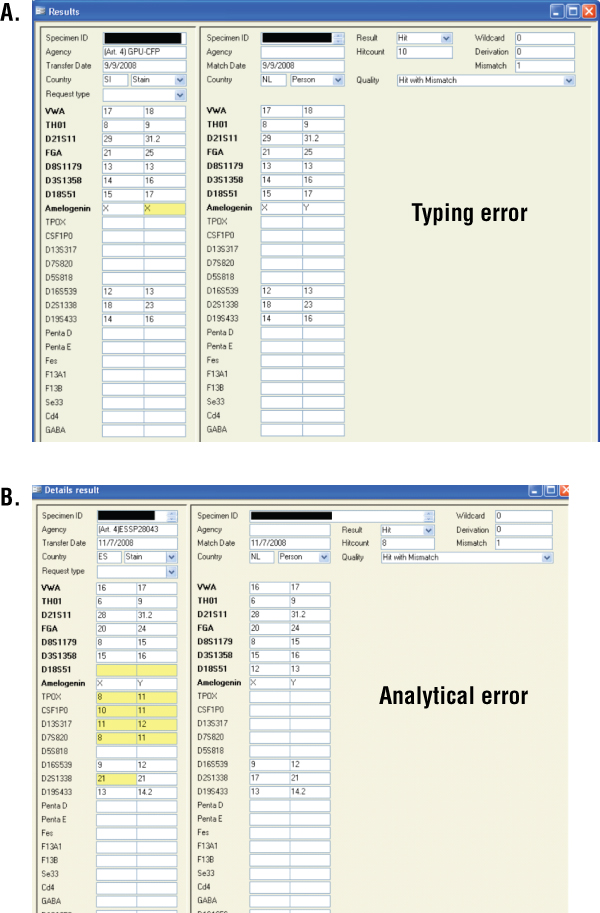 Figure 5. False-negative matches.
Figure 5. False-negative matches.
Panel A. False-negative match due to a typing error. Panel B. False-negative match due to an analytical error.
Primer binding-site mutations that cause allelic dropout when using one kit but not when using another kit also have been detected in this way.
Because mistakes are rare, near matches should not occur very frequently. Table 4 shows how many near matches have been found since the start of the Prüm operation in the Netherlands in 2008 until 1 July, 2011.
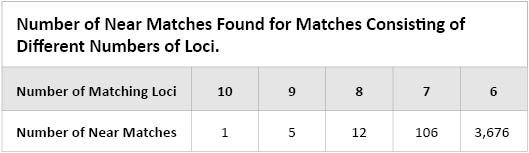 Table 4. Number of Near Matches Found on Matches Consisting of Different Numbers of Loci.
Table 4. Number of Near Matches Found on Matches Consisting of Different Numbers of Loci. It can be seen that 9- and 10-locus matches plus a mismatch are rare, and true false-negative matches have indeed been found amongst these type of matches. Near matches consisting of 8 or fewer loci plus a mismatch occur more frequently as the number of loci decreases, and the 3,676 matches consisting of 6 loci plus a mismatch constitute over one-third of all matches obtained on 1 July 2011 (10138). Statistical calculations have shown that the large number of 6-locus matches plus a mismatch is due to adventitious matching. So, what we are seeing here are false-positive false-negative matches, a whole new concept in statistics. The large number of 6-locus matches plus a mismatch is mainly caused by the fact that the German DNA database contains over 600,000 reference DNA profiles consisting of the seven ESS loci plus SE33. As Dutch DNA profiles normally do not contain SE33, there is only a 7-locus overlap between most Dutch and German DNA profiles. Excluding the 6-locus matches from the match results is not an option at this moment because the matching rules are fixed until all EU countries are operational. So in the Dutch daily practice these matches are ignored except when a stain from a Dutch case that is more serious than volume crime (burglary, car theft, etc.) matches a person in a foreign DNA database and the mismatch may be caused by an allelic dropout. One real false-negative match was found in this way amongst all 3,676 matches consisting of 6 loci plus a mismatch.
Conclusions
- An effective instrument has been developed and implemented for the comparison of European DNA databases.
- Additional testing of DNA profiles involved in 6- and 7-locus matches is needed to uncover false-positive matches.
- False-negative matches can be detected by allowing one mismatch (near match).
- Near matches consisting of 6 loci plus a mismatch are almost certainly false-positive false-negative matches and can be ignored. However, in serious cases it may be meaningful to do some additional DNA testing to prevent a true false-negative match from being undetected.
How to Cite This Article
Scientific Style and Format, 7th edition, 2006
van der Beek, C.P. Forensic DNA Profiles Crossing Borders in Europe (Implementation of the Treaty of Prüm). [Internet] 2011. [cited: year, month, date]. Available from: https://www.promega.com/resources/profiles-in-dna/2011/forensic-dna-profiles-crossing-borders-in-europe/
American Medical Association, Manual of Style, 10th edition, 2007
van der Beek, C.P. Forensic DNA Profiles Crossing Borders in Europe (Implementation of the Treaty of Prüm). Promega Corporation Web site. https://www.promega.com/resources/profiles-in-dna/2011/forensic-dna-profiles-crossing-borders-in-europe/ Updated 2011. Accessed Month Day, Year.
Contribution of an article to Profiles in DNA does not constitute an endorsement of Promega products.